Time measurement and delays are the backbone of how Linux and embedded systems actually work. This guide explains time measurement in a simple, practical way, covering kernel ticks, jiffies, Linux timers, and delay APIs with real-world meaning.
You will learn why systems need accurate time tracking, how delays are introduced without wasting CPU, and which delay methods are safe to use in user space and kernel space. Everything is explained in clear language, with examples that reflect real engineering work, not theory. Whether you are preparing for Linux kernel interviews or trying to write stable embedded code, this article helps you understand time and delays the way the operating system does.
Introduction: Why Time Measurement & Delays Matter More Than You Think
Time is invisible, but in computing systems, especially embedded and operating systems, time controls everything.
When you blink an LED, schedule a process, debounce a button, send an audio frame, or wait for hardware to stabilize, you are dealing with time measurement & delays. If time handling is wrong, systems become unstable, slow, power-hungry, or simply broken.
Most beginners treat delays as “just add sleep” and time as “just read a timer.” That works for demos, but real systems need precision, predictability, and efficiency .
By the end, you will think about time the same way the kernel does.
The Need for Time Measurement in Computing Systems
Let’s start with the most basic question.
Why do systems even need time measurement?
Imagine a system with no sense of time:
- Tasks would never expire
- Schedulers could not decide who runs next
- Network timeouts would never trigger
- Animations, audio, and video would break
This is why the need for time measurement exists at every level of software.
Core reasons time measurement is required
1. Task Scheduling
Operating systems decide which task runs and for how long. Without time measurement, fair scheduling is impossible.
2. Timeout Handling
Waiting forever for hardware or network responses is dangerous. Time measurement allows safe timeouts.
3. Performance Measurement
You cannot optimize what you cannot measure. Execution time, latency, and response time all depend on accurate clocks.
4. Synchronization
Protocols, distributed systems, and real-time tasks rely on timestamps to stay in sync.
5. Power Management
Sleep states, wakeup timers, and low-power modes all rely on time measurement.
In short, time measurement is not a feature. It is infrastructure.
Understanding Time from a System’s Point of View
Humans think in seconds and minutes. Computers don’t.
A system sees time as:
- Clock cycles
- Timer interrupts
- Counters
- Ticks
This abstraction is what allows software to reason about time.
Hardware clocks vs software time
Hardware clocks
- CPU clock
- System timer
- RTC (Real Time Clock)
These provide raw timing signals.
Software time
- Jiffies
- Ticks
- High resolution timers
Software layers convert hardware signals into usable time units.
This is where Time measurement & Delays becomes an OS responsibility.
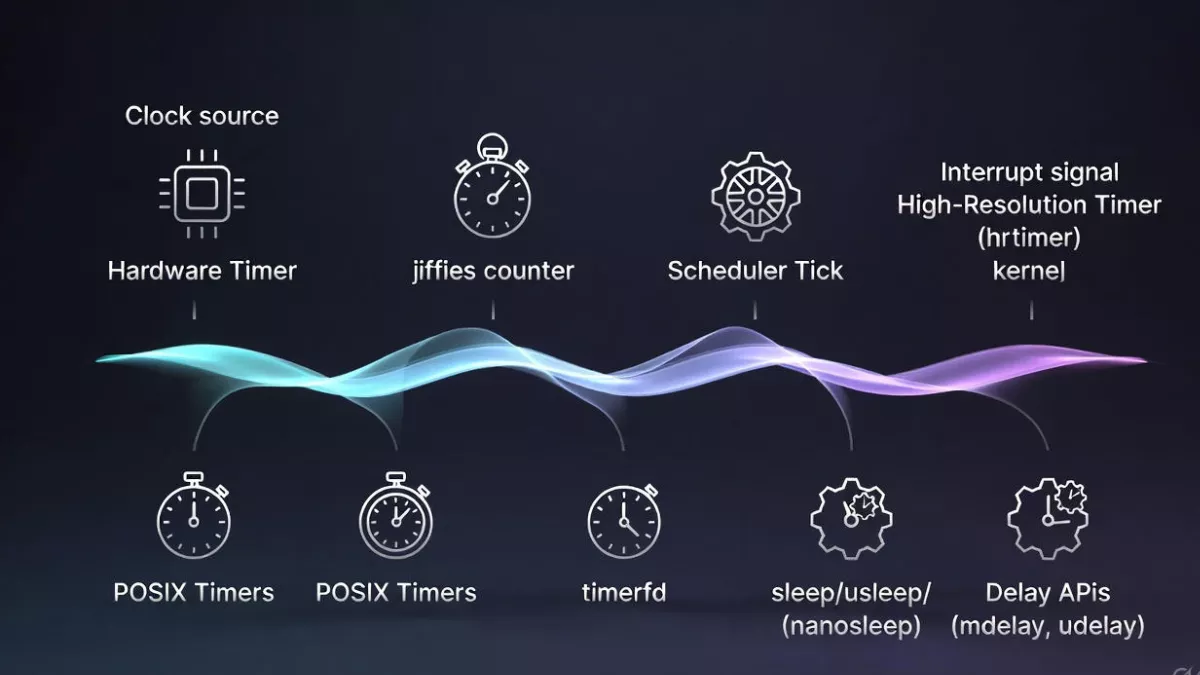
Kernel Tick: The Heartbeat of the Operating System
One of the most important concepts in time measurement is the kernel tick.
What is a kernel tick?
A kernel tick is a periodic interrupt generated by a hardware timer. Every tick tells the kernel:
“Another small unit of time has passed.”
Think of it like a heartbeat.
If the kernel tick is 1 ms, the kernel gets 1000 ticks per second.
Why the kernel tick exists
The kernel tick helps the OS:
- Update system time
- Preempt tasks
- Handle timers
- Trigger scheduling decisions
Without the kernel tick, the OS would be blind to time progression.
How Kernel Tick Works Internally
Let’s simplify this.
- Hardware timer fires an interrupt
- CPU switches to kernel mode
- Timer interrupt handler runs
- Kernel updates internal time counters
- Scheduler may run
- CPU resumes execution
This entire process happens thousands of times per second.
That is why kernel tick handling must be fast.
Kernel Tick Frequency and Its Impact
Kernel tick frequency is often represented as HZ.
Examples:
- HZ = 100 → tick every 10 ms
- HZ = 250 → tick every 4 ms
- HZ = 1000 → tick every 1 ms
Higher tick rate pros
- Better timing precision
- Smoother scheduling
- More responsive systems
Higher tick rate cons
- More interrupts
- Higher CPU overhead
- Increased power consumption
Choosing the right kernel tick rate is a balance, especially in embedded systems.
Tickless Kernel: A Modern Improvement
Older systems relied heavily on kernel ticks. Modern systems often use a tickless design.
What does tickless mean?
Instead of waking up at fixed intervals, the kernel sleeps until the next event.
This reduces:
- Unnecessary wakeups
- Power usage
- Interrupt overhead
Tickless kernels still support Time measurement & Delays, but more efficiently.
The Need for Delays in Real Systems
Now let’s talk about delays.
Why do we need delays at all?
At first glance, delays seem wasteful. But the need for delays is very real.
Common reasons include:
- Hardware stabilization
- Communication timing
- User experience
- Synchronization
Let’s break this down.
Hardware Stabilization Delays
Hardware does not react instantly.
Examples:
- Sensors need warm-up time
- PLLs need lock time
- Displays need initialization delays
Skipping these delays leads to undefined behavior.
This is one of the most common beginner mistakes.
Communication Timing Delays
Protocols often require timing gaps.
Examples:
- SPI chip select timing
- I2C setup and hold times
- UART baud rate stabilization
Here, delays are not optional. They are part of the protocol.
User Experience Delays
Sometimes delays are intentional.
Examples:
- Button debounce
- UI animations
- Status indication timing
These delays make systems feel natural instead of jittery.
Synchronization and Coordination
In concurrent systems, delays help coordinate events.
Examples:
- Waiting for a resource
- Polling with timeout
- Retrying after failure
This is where delay design becomes critical.
Introducing Delays: The Right Way vs the Wrong Way
Now comes the practical part.
Introducing delays incorrectly
The most common wrong approach is busy waiting.
for (int i = 0; i < 1000000; i++);
Problems:
- CPU is wasted
- Timing is unreliable
- Power usage spikes
Busy waits should be avoided unless absolutely necessary.
Introducing Delays Using Sleep Mechanisms
Operating systems provide sleep APIs for a reason.
User space delays
- sleep()
- usleep()
- nanosleep()
These allow the CPU to do useful work elsewhere.
Kernel space delays
- msleep()
- usleep_range()
- schedule_timeout()
These are safer and scheduler-friendly.
This is the correct way of introducing delays in most cases.
Delay Accuracy vs Delay Efficiency
Not all delays are equal.
Accurate delays
- Needed for hardware timing
- Short duration
- Often implemented using timers
Efficient delays
- Needed for waiting
- Longer duration
- CPU should sleep
Choosing the wrong type leads to bugs or inefficiency.
Delays in Embedded Systems
Embedded systems add another layer of complexity.
Bare-metal delays
- Timer based delays
- Cycle counting
- SysTick usage
RTOS delays
- vTaskDelay()
- Tick based scheduling
- Time slicing
Here, Time measurement & Delays are tightly coupled with system design.
Real Time Systems and Delay Guarantees
In real-time systems, delays are not just delays. They are deadlines.
Missing a delay window can cause:
- Data corruption
- Safety hazards
- System failure
That is why real-time kernels treat time as a first-class citizen.
Measuring Time Accurately
Delays are only as good as your time measurement.
Common time sources
- System clock
- Monotonic clock
- Hardware timers
What to avoid
- Wall clock for measuring durations
- Unstable clocks
- Low resolution timers
Always use monotonic time for measuring elapsed durations.
Time Drift and Its Effects
Time is never perfect.
Clocks drift due to:
- Temperature
- Voltage
- Hardware quality
Systems compensate using:
- Clock synchronization
- Periodic calibration
- RTC correction
Ignoring drift causes long-term issues.
Common Mistakes Beginners Make
Let’s call these out directly.
- Using busy loops for delays
- Assuming sleep is exact
- Ignoring scheduler behavior
- Mixing time units
- Using wall clock for performance measurement
Fixing these improves system reliability instantly.
Best Practices for Time Measurement & Delays
Here are rules that actually work.
- Measure time, don’t guess
- Sleep whenever possible
- Use kernel-provided timers
- Keep delays minimal
- Understand your scheduler
- Test under load
These apply across Linux, RTOS, and embedded platforms.
Time Measurement & Delays in Linux Kernel Context
In the Linux kernel:
- Kernel tick drives scheduling
- Timers manage delayed execution
- High resolution timers improve accuracy
Understanding these concepts helps you debug latency, audio glitches, and real-time issues.
Linux Timer Internals, Delay APIs, and Interview Q&A
Part 1: Linux Timer Internals Explained Like a Human
Why Linux Needs Timers at All
Linux is not sitting idle waiting for things to happen. It needs timers to:
- Wake up sleeping processes
- Enforce scheduling time slices
- Handle timeouts
- Measure time correctly
This entire system is built around time measurement & delays.
Core Building Blocks of Linux Timer Internals
1. Hardware Timers (The Foundation)
Linux does not create time from nothing. It relies on hardware timers such as:
- Programmable Interval Timer
- High Precision Event Timer (HPET)
- ARM generic timer
- TSC (Time Stamp Counter)
These timers generate interrupts or counters that Linux uses to track time.
2. Kernel Tick (Traditional Model)
Earlier Linux kernels used a fixed periodic interrupt called the kernel tick.
- Timer interrupt fires every X milliseconds
- Kernel updates internal time
- Scheduler decides task switching
- Timers are checked
This is where HZ comes into play.
Example:
HZ = 1000 → 1 tick every 1 ms
3. Tickless Kernel (Modern Linux)
Modern Linux uses a tickless kernel when possible.
Instead of waking up every millisecond:
- Kernel programs the timer for the next actual event
- CPU sleeps longer
- Power consumption drops
Tickless kernel still supports accurate time measurement & delays, just smarter.
4. Jiffies (Kernel’s Internal Time Unit)
Jiffies is a global counter incremented every tick.
- Type: unsigned long
- Unit: ticks
- Used heavily inside kernel
Example:
timeout = jiffies + msecs_to_jiffies(100);
Jiffies is fast, not precise. That’s intentional.
5. Timer Wheel (Efficient Timer Management)
Linux manages timers using a timer wheel concept.
Why?
- Thousands of timers may exist
- Checking all timers every tick is expensive
Timer wheel groups timers by expiration time, making timer handling efficient.
6. High Resolution Timers (hrtimers)
For accurate timing (audio, real-time tasks), Linux uses high resolution timers.
Features:
- Nanosecond precision
- Not limited by kernel tick
- Uses hardware timer directly
This is critical for modern multimedia and real-time systems.
7. Softirqs and Timers
Timer callbacks often run in softirq context.
This means:
- Cannot sleep
- Must be fast
- No blocking calls
Many kernel bugs happen because developers forget this.
Part 2: Linux Delay APIs Explained with Examples
Why Linux Has So Many Delay APIs
Because not all delays are the same.
Some delays:
- Must be accurate
- Must not block CPU
- Must allow scheduling
- Must be safe in interrupt context
One API cannot do everything.
User Space Delay APIs
1. sleep()
sleep(2);
- Sleeps for seconds
- Low precision
- Interrupted by signals
Use for simple user programs only.
2. usleep()
usleep(500000);
- Microsecond resolution
- Still not precise
- Deprecated in many cases
Avoid for new code.
3. nanosleep()
struct timespec ts = {0, 1000000};
nanosleep(&ts, NULL);
- Nanosecond interface
- Better control
- Still scheduler dependent
Best choice in user space.
Kernel Space Delay APIs (Very Important for Interviews)
1. mdelay()
mdelay(10);
- Busy wait
- CPU is blocked
- Accurate but inefficient
Only use for very short hardware delays.
2. udelay()
udelay(50);
- Microsecond busy wait
- Very precise
- Dangerous if used too long
Interview rule:
Never use udelay in large loops.
3. msleep()
msleep(100);
- Task sleeps
- CPU is free
- Scheduler friendly
Most commonly used delay in kernel code.
4. msleep_interruptible()
msleep_interruptible(100);
- Sleep can be interrupted by signals
- Used when responsiveness matters
5. usleep_range()
usleep_range(1000, 2000);
- Best practice for short delays
- Allows scheduler flexibility
- Power efficient
This is preferred over udelay in modern kernels.
6. schedule_timeout()
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(msecs_to_jiffies(100));
- Low-level API
- Full control
- Used inside kernel subsystems
Choosing the Right Delay API (Interview Gold)
| Requirement | API |
|---|---|
| Very short hardware delay | udelay |
| Short but flexible delay | usleep_range |
| Long delay | msleep |
| Precise timing | hrtimer |
| User space | nanosleep |
Part 3: Linux Timer Interview Questions and Answers
ROUND 1: Basic to Intermediate Questions
Q1. Why does Linux need timers?
Answer:
Linux needs timers to track time, schedule processes, handle timeouts, manage delays, and support real-time behavior. Without timers, multitasking would not work.
Q2. What is a kernel tick?
Answer:
A kernel tick is a periodic timer interrupt that tells the kernel that a small unit of time has passed. It is used for scheduling, time accounting, and timer management.
Q3. What is HZ in Linux?
Answer:
HZ defines how many timer interrupts occur per second. For example, HZ = 1000 means one tick every millisecond.
Q4. What are jiffies?
Answer:
Jiffies is a kernel variable that counts the number of ticks since system boot. It is used internally for timing calculations.
Q5. Difference between busy wait and sleep?
Answer:
Busy wait wastes CPU cycles while sleep allows the scheduler to run other tasks. Busy wait is accurate but inefficient.
Q6. Why is mdelay dangerous?
Answer:
Because it blocks the CPU and prevents other tasks from running, which can cause latency and power issues.
Q7. What is tickless kernel?
Answer:
A tickless kernel avoids periodic timer interrupts when the system is idle and wakes up only when needed, improving power efficiency.
ROUND 2: Advanced & Kernel-Level Questions
Q1. Why does Linux prefer usleep_range over udelay?
Answer:
usleep_range allows the scheduler flexibility and reduces power usage, while udelay is a busy wait and blocks the CPU.
Q2. Can you sleep in interrupt context?
Answer:
No. Sleeping in interrupt context is not allowed because interrupts must execute quickly and cannot block.
Q3. What context do timer callbacks run in?
Answer:
Most timer callbacks run in softirq context, which means they cannot sleep and must be fast.
Q4. How does Linux achieve high resolution timers?
Answer:
Linux uses hardware timers directly through hrtimers instead of relying on kernel ticks, allowing nanosecond precision.
Q5. What happens if HZ is too high?
Answer:
Higher HZ increases timer interrupts, CPU overhead, and power consumption.
Q6. Why should wall clock not be used for measuring execution time?
Answer:
Wall clock can change due to NTP or user adjustment. Monotonic clock always moves forward and is reliable.
Q7. How does schedule_timeout work internally?
Answer:
It sets the task state and puts the process to sleep until the specified number of jiffies expires or a signal wakes it.
Q8. When should hrtimers be used?
Answer:
When precise timing is required, such as audio playback, real-time scheduling, or hardware synchronization.
Q9. What are common timer-related bugs?
Answer:
- Sleeping in atomic context
- Using udelay for long delays
- Timer callback doing heavy work
- Incorrect time unit conversion
Q10. How does time measurement affect audio or real-time systems?
Answer:
Incorrect timing causes jitter, buffer underruns, missed deadlines, and unstable system behavior.
Frequently Asked Questions (FAQ) on Time Measurement & Delays
1. What is time measurement in Linux systems?
Time measurement in Linux is the way the operating system tracks the passage of time to schedule tasks, manage delays, handle timeouts, and measure performance. It is done using hardware timers, kernel ticks, and software counters.
2. Why is time measurement important in operating systems?
Time measurement is important because without it the system cannot schedule processes, enforce timeouts, or coordinate hardware and software correctly. Almost every OS feature depends on accurate timing.
3. What is a kernel tick in Linux?
A kernel tick is a periodic timer interrupt that informs the Linux kernel that a fixed amount of time has passed. It helps the kernel update time, run the scheduler, and manage timers.
4. What does HZ mean in the Linux kernel?
HZ defines how many kernel ticks occur per second. For example, HZ = 1000 means the kernel receives one tick every millisecond, which improves timing accuracy but increases CPU overhead.
5. What are jiffies and why are they used?
Jiffies are a kernel variable that counts the number of ticks since system boot. They are fast and efficient, making them ideal for internal kernel time calculations.
6. Why does Linux use a tickless kernel?
Linux uses a tickless kernel to reduce unnecessary timer interrupts when the system is idle. This improves power efficiency and reduces CPU usage while still maintaining accurate time measurement.
7. What is the need for delays in Linux and embedded systems?
Delays are needed to allow hardware to stabilize, manage communication timing, debounce inputs, and synchronize tasks. Without proper delays, systems can behave unpredictably.
8. What is the difference between busy wait and sleep delays?
Busy wait delays keep the CPU active and waste processing power, while sleep delays allow the scheduler to run other tasks. Sleep-based delays are preferred in most cases.
9. Which delay API should be used inside the Linux kernel?
For short delays, usleep_range() is preferred. For longer delays, msleep() is commonly used. Busy wait functions like udelay() should only be used for very short hardware-specific delays.
10. Can a kernel timer callback sleep?
No, kernel timer callbacks usually run in softirq context, where sleeping is not allowed. Timer callbacks must execute quickly and avoid blocking operations.
11. Why is monotonic time preferred over wall clock time?
Monotonic time always moves forward and is not affected by system time changes. Wall clock time can change due to NTP or manual updates, making it unreliable for measuring durations.
12. How do time measurement and delays affect system performance?
Incorrect handling of time and delays can cause high CPU usage, poor responsiveness, audio glitches, missed deadlines, and increased power consumption. Proper time management leads to stable and efficient systems.
Read More about Process : What is is Process
Read More about System Call in Linux : What is System call
Read More about IPC : What is IPC
Mr. Raj Kumar is a highly experienced Technical Content Engineer with 7 years of dedicated expertise in the intricate field of embedded systems. At Embedded Prep, Raj is at the forefront of creating and curating high-quality technical content designed to educate and empower aspiring and seasoned professionals in the embedded domain.
Throughout his career, Raj has honed a unique skill set that bridges the gap between deep technical understanding and effective communication. His work encompasses a wide range of educational materials, including in-depth tutorials, practical guides, course modules, and insightful articles focused on embedded hardware and software solutions. He possesses a strong grasp of embedded architectures, microcontrollers, real-time operating systems (RTOS), firmware development, and various communication protocols relevant to the embedded industry.
Raj is adept at collaborating closely with subject matter experts, engineers, and instructional designers to ensure the accuracy, completeness, and pedagogical effectiveness of the content. His meticulous attention to detail and commitment to clarity are instrumental in transforming complex embedded concepts into easily digestible and engaging learning experiences. At Embedded Prep, he plays a crucial role in building a robust knowledge base that helps learners master the complexities of embedded technologies.